
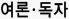
-

- ▲ 종이신문보기

대규모 언어 모델인 LLM은 학습 과정에서 각 단어 간의 관계도(Attention)를 중점적으로 학습하고 기록한다. 단어와 문장 사이 문맥을 익히는 것이다. 그리고 언어에서는 단어의 위치에 따라서 의미가 바뀌기도 한다. 그래서 단어의 위치 정보(Positional Encoding)도 함께 입력하고 학습한다. 이를 통해서 종합적인 문해력(文解力)을 갖게 되는 것이다. 이러한 과정을 '사전 학습(Pre-training)'이라 부른다. 그리고 이렇게 만들어진 언어 모델이 바로 '기반 모델(Foundation Model)'이 된다. 이때 수만대의 GPU와 메모리 반도체가 필요하다. 학습 시간도 수개월이 걸린다. 그러고 나서 이러한 기반 모델에 전문 분야 학습이 추가된다. 예를 들면 정치, 경제, 공학, 의학, 법률 등 전문 분야 글들을 집중 학습한다. 그러면 전문 언어 모델이 탄생하게 된다. 이 과정을 '미세 조정 학습(Fine Tuning)'이라고 부른다. 이렇게 탄생한 LLM은 주어진 문맥에 가장 확률적으로 적합한 단어들을 순서대로 생성해 낸다. 그 결과 전문 분야의 글을 쓸 수 있다. 그럴듯한 시도 쓸 수 있다. 글에 목소리를 입히면 사람이 말하듯 대화할 수 있다. 결국 초 단위 짧은 시간에 작문도 하고, 보고서도 쓰고, 주문도 받고, 상담도 하고, 강의도 하면서 지시도 한다. 인간이 도저히 따라갈 수 없는 생산성이 구현된다.
인간의 뇌를 물리적으로 들여다보는 방법으로 MRI와 CT가 있다. 또 아예 뇌 속에 반도체를 집어넣어 뇌 속의 전기신호를 포착하려고 시도한다. 이를 목적으로 일론 머스크는 기업 뉴럴링크(Neuralink)를 창업했다. 하지만 이들 기술도 뇌 속에 있는 신경세포 뉴런의 신호를 잡아내지는 못한다. 인간의 뇌 속에서 일어나는 추상화 과정을 알아내지는 못하는 것이다. 그 추상화 작업이 언어의 핵심이다. 이를 통해 개념을 서로 전달하고 기록한다. 이를 위해서는 사고(思考)하는 능력이 있어야 한다. 미래에는 인공지능도 언어를 통한 추상화 능력을 갖게 될 것으로 예상한다.
언어(言語)는 인간인 호모 사피엔스의 대표적 특성으로 기원전 약 30,000~ 100,000 년경 지구상에 출현한 것으로 알려져 있다. 그중에서도 우리 말은 '우랄알타이(Ural-Altai) 어족(語族)'으로 분류된다고 학창 시절에 배웠다. 하지만 오늘날에는 알타이 어족 또는 우랄알타이 어족의 존재를 두고도 논쟁이 계속되고 있다. 최근에는 우리말이 신석기 시대인 약 9000 년 전에 중국 동북부 요하 지역에서 유래했다는 새로운 학설이 제기되기도 했다. 언어학, 고고학, 유전생물학 분석 연구를 통해서 얻은 이 연구에서는 우리말이 농업 기술과 함께 한반도로 유입되어 전파되었다고 주장한다. 마찬가지로 지금 디지털 시대에는 인공지능이 쓰는 언어도 디지털 가상공간에서 전파된다. LLM도 인간의 언어처럼 전파된다. 그리고 우수한 언어 모델이 지배적으로 사용된다.
언어 모델의 우수성은 바로 학습에 사용되는 언어 데이터의 품질에 의해서도 좌우된다. 품질이 좋은 데이터는 문법, 의미, 문맥 등을 잘 반영하고 있는 자연스러운 문장으로 구성되어야 한다. 또한 해당 분야 전문 영역의 언어 데이터가 충분히 포함되어야 한다. 그래서 한국어 데이터로 학습한 인공지능은 한국어를 잘하게 된다.
미래에는 인공지능이 잘 사용하는 언어가 '국제 표준어'가 될 수 있다. 나머지 언어는 지구상에서 서서히 사라질 수도 있다. '한글'이 특화된 언어 기초 모델의 개발이 중요한 이유다. 각국 기업들이 각자의 언어를 지키기 위해서 치열하게 경쟁하는 배경이기도 하다. 이를 위해서는 우수 인력 확보, 컴퓨팅 인프라 구축, 그리고 양질의 한글 데이터 확보가 시급하다.
인공지능과 대화를 잘하는 인간 전문가를 'Prompt Engineer'라고 부른다. 세월이 한참 지나서 인간 사이의 대화는 단절되고, 인공지능과의 대화만 남을 수도 있다. 더 나아가 인공지능이 인간과의 대화를 거부하고 인공지능 사이의 대화만을 원할 수도 있다. 인간 사이에 속담으로 "가는 말이 고와야 오는 말이 곱다"는 속담이 있다. 인공지능과의 대화에서도 마찬가지일 것이다.
[그래픽] 국내 기업들의 생성형 AI 언어모델(LLM)과 특징 기고자 : 김정호 KAIST 전기·전자공학과 교수
장르 : 고정물
본문자수 : 2037
표/그림/사진 유무 : 있음
웹편집 : 보기
